第 11 章。數字
JavaScript 將所有數字視為浮點數,只使用單一類型。然而,如果小數點後沒有數字,則不會顯示小數點:
> 5.000 5
在內部,大多數 JavaScript 引擎會最佳化並區分浮點數和整數(詳細資訊:JavaScript 中的整數)。但這不是程式設計師會看到的。
JavaScript 數字是 double(64 位元)值,根據 IEEE 浮點數運算標準(IEEE 754)。許多程式語言都使用此標準。
數字文字
數字文字可以 是整數、浮點數或(整數)十六進位數:
> 35 // integer 35 > 3.141 // floating point 3.141 > 0xFF // hexadecimal 255
呼叫文字的函式
對於數字文字,用於存取屬性的點必須與小數點區分。如果您要在數字文字 123 上呼叫 toString(),則有下列選項:
123..toString()123.toString()// space before the dot123.0.toString()(123).toString()
轉換為數字
| 值 | 結果 |
|
|
|
|
布林值 |
|
| |
數字 | 與輸入相同(無需轉換) |
字串 | 分析字串中的數字(忽略前導和尾隨空白);空字串會轉換為 0。範例: |
物件 | 呼叫 |
當將空字串轉換為數字時,NaN 可能是較好的結果。選擇結果 0 是為了協助處理空的數字輸入欄位,這與 1990 年代中期其他程式語言的做法一致。[14]
手動轉換為數字
將任何值轉換為數字的兩種最常見方式是:
| (作為函式呼叫,而非建構函式) |
|
我比較喜歡 Number(),因為它比較具描述性。以下是幾個範例
> Number('')
0
> Number('123')
123
> Number('\t\v\r12.34\n ') // ignores leading and trailing whitespace
12.34
> Number(false)
0
> Number(true)
1parseFloat()
全域函式 parseFloat() 提供另一種將值轉換為數字的方法。不過,Number() 通常是較好的選擇,我們稍後會看到。這段程式碼:
parseFloat(str)
將 str 轉換為字串,修剪開頭空白,然後分析最長的浮點數字首。如果沒有這樣的字首(例如,在空字串中),則會傳回 NaN。
比較 parseFloat() 和 Number()
將
parseFloat()套用至非字串較不有效率,因為它會在分析之前強制轉換其引數為字串。因此,Number()轉換為實際數字的許多值會被parseFloat()轉換為NaN> parseFloat(true) // same as parseFloat('true') NaN > Number(true) 1 > parseFloat(null) // same as parseFloat('null') NaN > Number(null) 0parseFloat()將空字串分析為NaN> parseFloat('') NaN > Number('') 0parseFloat()會分析至最後一個合法字元,表示您可能會在不想要結果時取得結果> parseFloat('123.45#') 123.45 > Number('123.45#') NaNparseFloat()會忽略開頭空白,並在非法字元(包括空白)之前停止> parseFloat('\t\v\r12.34\n ') 12.34Number()會忽略開頭和結尾空白(但其他非法字元會導致NaN)。
特殊數字值
JavaScript 有幾個特殊數字值:
-
兩個錯誤值,
NaN和Infinity。 -
零有兩個值,
+0和-0。JavaScript 有兩個零,一個正零和一個負零,因為數字的符號和大小是分開儲存的。在這本書的大部分章節中,我假裝只有一個零,而且你幾乎不會在 JavaScript 中看到兩個零。
NaN
錯誤 值 NaN(「不是數字」的縮寫)具有諷刺意味的是一個數字值:
> typeof NaN 'number'
它是由以下錯誤產生的
無法解析數字
> Number('xyz') NaN > Number(undefined) NaN操作失敗
> Math.acos(2) NaN > Math.log(-1) NaN > Math.sqrt(-1) NaN
其中一個運算元是
NaN(這確保如果在較長的運算期間發生錯誤,你可以在最終結果中看到它)> NaN + 3 NaN > 25 / NaN NaN
陷阱:檢查值是否為 NaN
NaN 是唯一一個 不與自身相等的值:
> NaN === NaN false
嚴格相等(===)也由 Array.prototype.indexOf 使用。因此,你無法透過該方法在陣列中搜尋 NaN
> [ NaN ].indexOf(NaN) -1
如果你想檢查值是否為 NaN,你必須使用全域 函式 isNaN():
> isNaN(NaN) true > isNaN(33) false
但是,isNaN 無法正確處理非數字,因為它會先將這些轉換為數字。該轉換可能會產生 NaN,然後函式會不正確地傳回 true
> isNaN('xyz')
true因此,最好將 isNaN 與 類型檢查結合使用:
functionmyIsNaN(value){returntypeofvalue==='number'&&isNaN(value);}
或者,你可以檢查該值是否不與自身相等(因為 NaN 是具有此特徵的唯一值)。但那樣 較難理解:
functionmyIsNaN(value){returnvalue!==value;}
請注意,此行為是由 IEEE 754 規定的。如第 7.11 節「比較謂詞的詳細資訊」中所述:[15]
每個 NaN 都應與所有事物(包括自身)進行無序比較。
無限大
Infinity 是表示兩個問題之一的錯誤值:無法表示數字,因為其大小太大,或者發生了除以零的運算。
Infinity 大於任何其他數字(NaN 除外)。同樣地,-Infinity 小於任何其他數字(NaN 除外)。這讓它們可用作預設值,例如,當您在尋找最小值或最大值時。
錯誤:數字的絕對值太大
數字的絕對值能變多大是由其內部表示法決定的(如 數字的內部表示法 中所討論的),它是
- 尾數(一個二進制數字 1.f1f2...)
- 2 的指數次方
指數必須介於(且排除)−1023 和 1024 之間。如果指數太小,數字將變為 0。如果指數太大,它將變為 Infinity。21023 仍可表示,但 21024 則不行
> Math.pow(2, 1023) 8.98846567431158e+307 > Math.pow(2, 1024) Infinity
使用 Infinity 進行運算
如果您嘗試使用另一個 Infinity 來「中和」一個 Infinity,您將得到 錯誤結果 NaN:
> Infinity - Infinity NaN > Infinity / Infinity NaN
如果您嘗試超越 Infinity,您仍會得到 Infinity
> Infinity + Infinity Infinity > Infinity * Infinity Infinity
檢查 Infinity
嚴格和寬鬆相等 對 Infinity 有效:
> var x = Infinity; > x === Infinity true
此外,全域函數 isFinite() 允許您檢查一個值是否是一個實際數字(既不是無限大也不是 NaN):
> isFinite(5) true > isFinite(Infinity) false > isFinite(NaN) false
兩個零
由於 JavaScript 的數字保持 絕對值和符號分開,每個非負數字都有負數,包括 0。
這樣做的理由是,無論何時以數位方式表示數字,它都可能變得如此小以至於無法與 0 區分,因為編碼不夠精確無法表示差異。然後,一個有符號的零允許您記錄「從哪個方向」接近零;也就是說,在數字被視為零之前它有什麼符號。維基百科很好地總結了 有符號零 的優缺點
聲稱在 IEEE 754 中包含有號零,在某些關鍵問題中,特別是在使用複雜基本函數進行運算時,可以更輕鬆地實現數值精確度。另一方面,有號零的概念與大多數數學領域(以及大多數數學課程)中做出的負零等於零的一般假設相悖。允許負零的表示法會導致程式出現錯誤,因為軟體開發人員沒有意識到(或可能忘記),儘管兩個零表示法在數值比較中表現得相同,但它們是不同的位模式,並且在某些運算中會產生不同的結果。
最佳實務:假裝只有一個零
JavaScript 費盡心思隱藏了存在兩個零的事實。由於它們不同通常無關緊要,建議您配合單一零的錯覺。讓我們探討如何維持這種錯覺。
在 JavaScript 中,您通常會寫 0,表示 +0。但 -0 也會顯示為 0。這是您在使用瀏覽器命令列或 Node.js REPL 時所看到的
> -0 0
這是因為標準 toString() 方法會將 兩個零都轉換為相同的 '0':
> (-0).toString() '0' > (+0).toString() '0'
相等性也不會區分 零。甚至 === 也不行:
> +0 === -0 true
Array.prototype.indexOf 使用 === 搜尋元素,維持錯覺
> [ -0, +0 ].indexOf(+0) 0 > [ +0, -0 ].indexOf(-0) 0
排序運算子也認為零相等
> -0 < +0 false > +0 < -0 false
區分兩個零
您 如何 實際觀察到兩個零不同?您可以除以零(-Infinity 和 +Infinity 可以 用 === 區分):
> 3 / -0 -Infinity > 3 / +0 Infinity
執行零除法的另一種方式是透過 Math.pow() (請參閱 數值函數)
> Math.pow(-0, -1) -Infinity > Math.pow(+0, -1) Infinity
Math.atan2() (請參閱 三角函數) 也顯示零有不同:
> Math.atan2(-0, -1) -3.141592653589793 > Math.atan2(+0, -1) 3.141592653589793
區分兩個零的標準方式是零除法。因此,偵測負零的函數看起來像這樣:
functionisNegativeZero(x){returnx===0&&(1/x<0);}
以下是函數的使用方式
> isNegativeZero(0) false > isNegativeZero(-0) true > isNegativeZero(33) false
數字的內部表示法
JavaScript 數字具有 64 位元精確度,也稱為雙精度(在某些程式語言中為 double 類型)。內部表示法基於 IEEE 754 標準。64 位元分佈在數字的符號、指數和分數中,如下所示:
| 符號 | 指數 ∈ [−1023, 1024] | 分數 |
1 位元 | 11 位元 | 52 位元 |
第 63 位元 | 第 62–52 位元 | 第 51–0 位元 |
數字的值由下列公式計算
(–1)符號 × %1.分數 × 2指數
百分比符號 (%) 表示中間的數字以二進位表示法寫成:1,後接二進位點,後接二進位分數,也就是分數的二進位數位(自然數)。以下是此表示法的幾個範例:
+0 | (符號 = 0,分數 = 0,指數 = −1023) | |
–0 | (符號 = 1,分數 = 0,指數 = −1023) | |
1 | = (−1)0 × %1.0 × 20 | (符號 = 0,分數 = 0,指數 = 0) |
2 | = (−1)0 × %1.0 × 21 | |
3 | = (−1)0 × %1.1 × 21 | (符號 = 0,分數 = 251,指數 = 0) |
0.5 | = (−1)0 × %1.0 × 2−1 | |
−1 | = (−1)1 × %1.0 × 20 |
+0、−0 和 3 的編碼可以說明如下
- ±0:由於分數總是會加上 1 作為前綴,因此無法用它來表示 0。因此,JavaScript 會透過分數 0 和特殊指數 −1023 來編碼 0。符號可以是正或負,這表示 JavaScript 有兩個 0(請參閱 兩個 0)。
- 3:第 51 位元是分數中最重要的(最高)位元。該位元為 1。
特殊指數
先前提到的數字表示法稱為 正規化。在這種情況下,指數 e 的範圍為 −1023 < e < 1024(不含上下界)。−1023 和 1024 是特殊指數:
-
1024 用於錯誤值,例如
NaN和Infinity。 −1023 用於
- 0(如果分數為 0,如剛才所述)
- 接近 0 的小數字(如果分數不為 0)。
為了支援這兩個應用程式,會使用不同的、所謂的 非正規化 表示法:
(–1)符號 × %0.fraction × 2–1022
相較之下,正規化表示法中最小(即「最接近 0」)的數字為
(–1)符號 × %1.fraction × 2–1022
非正規化數字較小,因為沒有前導數字 1。
處理捨入誤差
JavaScript 的數字通常以十進位浮點數字輸入,但它們在內部表示為二進位浮點數字。這會導致不精確。為了了解原因,讓我們忘記 JavaScript 的內部儲存格式,並從一般角度來看十進位浮點數字和二進位浮點數字可以很好地表示哪些分數。在十進位系統中,所有分數都是尾數 m 除以 10 的次方:
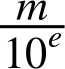
因此,在分母中,只有十位數。這就是為什麼 ![]() 無法精確表示為十進位浮點數字的原因,因為無法在分母中放入 3。二進位浮點數字在分母中只有二位數。讓我們檢查哪些十進位浮點數字可以很好地表示為二進位,哪些不能。如果分母中只有二位數,則可以表示十進位數字
無法精確表示為十進位浮點數字的原因,因為無法在分母中放入 3。二進位浮點數字在分母中只有二位數。讓我們檢查哪些十進位浮點數字可以很好地表示為二進位,哪些不能。如果分母中只有二位數,則可以表示十進位數字
-
0.5dec =
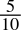 =
= 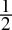 = 0.1bin
= 0.1bin
-
0.75dec =
 =
= 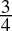 = 0.11bin
= 0.11bin
-
0.125dec =
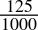 =
= 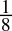 = 0.001bin
= 0.001bin
其他分數無法精確表示,因為它們在分母中具有 2 以外的數字(在質因數分解後)
-
0.1dec =
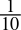 =
= 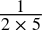
-
0.2dec =
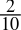 =
= 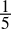
您通常看不到 JavaScript 在內部沒有精確儲存 0.1。但您可以透過將它乘以 10 的夠高次方使其可見
> 0.1 * Math.pow(10, 24) 1.0000000000000001e+23
而且如果您新增兩個不精確表示的數字,結果有時會不精確到不精確度變得可見
> 0.1 + 0.2 0.30000000000000004
另一個範例
> 0.1 + 1 - 1 0.10000000000000009
由於捨入誤差,作為最佳實務,您不應直接比較非整數。相反地,考量捨入誤差的上限。此類上限稱為機器 epsilon。雙精度標準epsilon 值為 2−53:
varEPSILON=Math.pow(2,-53);functionepsEqu(x,y){returnMath.abs(x-y)<EPSILON;}
epsEqu() 確保正確的結果,在正常比較會不足夠的情況下
> 0.1 + 0.2 === 0.3 false > epsEqu(0.1+0.2, 0.3) true
JavaScript 中的整數
如前所述,JavaScript 只有浮點數。整數在內部以兩種方式出現。首先,大多數 JavaScript 引擎會將沒有小數部分的夠小數字儲存為整數(例如,31 位元),並盡可能維持該表示法。如果數字的數量級變大或出現小數部分,它們必須切換回浮點表示法。
其次,ECMAScript 規範具有整數運算子:即所有位元運算子。這些運算子會將其運算元轉換為 32 位元整數,並傳回 32 位元整數。對於規範而言,整數 僅表示數字沒有小數部分,而 32 位元 表示它們在特定範圍內。對於引擎而言,32 位元整數 表示通常可以引入或維護實際整數(非浮點)表示法。
將整數表示為浮點數
JavaScript 只能處理最高 53 位元大小的整數值(小數部分的 52 位元加上 1 個間接位元,透過指數;請參閱 數字的內部表示法 以取得詳細資訊)。
下表說明 JavaScript 如何將 53 位元整數表示為浮點數
| 位元 | 範圍 | 編碼 |
1 位元 | 0 | (請參閱 數字的內部表示法。) |
1 位元 | 1 | %1 × 20 |
2 位元 | 2–3 | %1.f51 × 21 |
3 位元 | 4–7 = 22–(23−1) | %1.f51f50 × 22 |
4 位元 | 23–(24−1) | %1.f51f50f49 × 23 |
⋯ | ⋯ | ⋯ |
53 位元 | 252–(253−1) | %1.f51⋯f0 × 252 |
沒有固定位元順序代表整數。取而代之的是,尾數 %1.f 會由指數位移,讓首位數字 1 出現在正確位置。在某種程度上,指數會計算分數中正在使用中的數字位數(其餘數字為 0)。這表示對於 2 位元,我們使用分數的一位數字,而對於 53 位元,我們使用分數的所有數字。此外,我們可以將 253 表示為 %1.0 × 253,但我們會遇到較大數字的問題
| 位元 | 範圍 | 編碼 |
54 位元 | 253–(254−1) | %1.f51⋯f00 × 253 |
55 位元 | 254–(255−1) | %1.f51⋯f000 × 254 |
⋯ |
對於 54 位元,最不顯著的數字永遠是 0,對於 55 位元,兩個最不顯著的數字永遠是 0,依此類推。這表示對於 54 位元,我們只能表示每一個第二個數字,對於 55 位元只能表示每一個第四個數字,依此類推。例如
> Math.pow(2, 53) - 1 // OK 9007199254740991 > Math.pow(2, 53) // OK 9007199254740992 > Math.pow(2, 53) + 1 // can't be represented 9007199254740992 > Math.pow(2, 53) + 2 // OK 9007199254740994
安全整數
JavaScript 只能安全地表示範圍為 −253 < i < 253 的整數 i。 本節探討這表示什麼以及後果是什麼。它是根據 Mark S. Miller 寄給 es-discuss 郵件清單的電子郵件。
安全整數的概念集中在數學整數在 JavaScript 中的表示方式。在範圍 (−253, 253)(不包括下界和上界)中,JavaScript 整數是 安全的:數學整數及其在 JavaScript 中的表示之間存在一對一的對應。
超出此範圍,JavaScript 整數是 不安全的:兩個或多個數學整數表示為相同的 JavaScript 整數。例如,從 253 開始,JavaScript 只能表示每一個第二個數學整數(前一節說明原因)。因此,安全的 JavaScript 整數是明確表示單一數學整數的整數。
ECMAScript 6 中的定義
ECMAScript 6 將提供下列常數:
Number.MAX_SAFE_INTEGER=Math.pow(2,53)-1;Number.MIN_SAFE_INTEGER=-Number.MAX_SAFE_INTEGER;
它還將提供一個函數,用於確定一個整數是否安全:
Number.isSafeInteger=function(n){return(typeofn==='number'&&Math.round(n)===n&&Number.MIN_SAFE_INTEGER<=n&&n<=Number.MAX_SAFE_INTEGER);}
對於給定的值 n,此函數首先檢查 n 是否為數字和整數。如果兩個檢查都成功,則 n 是安全的,如果它大於或等於 MIN_SAFE_INTEGER 且小於或等於 MAX_SAFE_INTEGER。
算術運算的安全結果
我們如何確保算術運算的結果正確?例如,以下結果明顯不正確:
> 9007199254740990 + 3 9007199254740992
我們有兩個安全的運算元,但結果不安全
> Number.isSafeInteger(9007199254740990) true > Number.isSafeInteger(3) true > Number.isSafeInteger(9007199254740992) false
以下結果也不正確
> 9007199254740995 - 10 9007199254740986
這次,結果是安全的,但運算元之一不是
> Number.isSafeInteger(9007199254740995) false > Number.isSafeInteger(10) true > Number.isSafeInteger(9007199254740986) true
因此,僅當所有運算元和結果都安全時,應用整數運算元 op 的結果才保證正確。更正式地說
isSafeInteger(a) && isSafeInteger(b) && isSafeInteger(a op b)
暗示 a op b 是正確的結果。
轉換為整數
在 JavaScript 中,所有數字都是浮點數。整數是沒有小數的浮點數。將數字 n 轉換為整數表示尋找「最接近」n 的整數(其中「最接近」的含義取決於轉換方式)。您有幾個選項可以執行此轉換:
-
Math函數Math.floor()、Math.ceil()和Math.round()(請參閱透過 Math.floor()、Math.ceil() 和 Math.round() 處理整數) -
自訂函數
ToInteger()(請參閱透過自訂函數 ToInteger() 處理整數) - 二進位按位元運算子(請參閱透過按位元運算子處理 32 位元整數)
-
全域函數
parseInt()(請參閱透過 parseInt() 處理整數)
提示:#1 通常是最佳選擇,#2 和 #3 有利基應用,而 #4 適用於剖析字串,但不適用於將數字轉換為整數。
透過 Math.floor()、Math.ceil() 和 Math.round() 處理整數
以下三個函數通常是將數字轉換為整數的最佳方式
Math.floor()將其參數轉換為 最接近的較低整數:> Math.floor(3.8) 3 > Math.floor(-3.8) -4
Math.ceil()將其參數轉換為 最接近的較高整數:> Math.ceil(3.2) 4 > Math.ceil(-3.2) -3
Math.round()將其參數轉換為 最接近的整數:> Math.round(3.2) 3 > Math.round(3.5) 4 > Math.round(3.8) 4
捨入
-3.5的結果可能令人驚訝> Math.round(-3.2) -3 > Math.round(-3.5) -3 > Math.round(-3.8) -4
因此,
Math.round(x)與Math.floor(x+0.5)
透過自訂函數 ToInteger() 取得整數
將任何值轉換為整數的另一個好方法是內部 ECMAScript 作業 ToInteger(),它會移除浮點數的小數部分。如果它可以在 JavaScript 中使用,它會像這樣運作:
> ToInteger(3.2) 3 > ToInteger(3.5) 3 > ToInteger(3.8) 3 > ToInteger(-3.2) -3 > ToInteger(-3.5) -3 > ToInteger(-3.8) -3
ECMAScript 規格將 ToInteger(number) 的結果定義為
sign(number) × floor(abs(number))
對於它的功能,這個公式相對複雜,因為 floor 尋找最接近的 較大 整數;如果您想要移除負整數的小數部分,您必須尋找最接近的較小整數。以下程式碼在 JavaScript 中實作此作業。如果數字為負數,我們使用 ceil 來避免 sign 作業
functionToInteger(x){x=Number(x);returnx<0?Math.ceil(x):Math.floor(x);}
二進位位元運算子(請參閱 二進位位元運算子)將(至少)一個運算元轉換為 32 位元整數,然後對其進行處理以產生也是 32 位元整數的結果。因此,如果您適當地選擇另一個運算元,您將獲得一種將任意數字轉換為 32 位元整數(有符號或無符號)的快速方法。
位元或 (|)
如果遮罩(第二個運算元)為 0,您不會變更任何位元,結果為第一個運算元,強制轉換為有符號 32 位元整數。 這是執行這種強制轉換的標準方法,例如,asm.js 使用它(請參閱 JavaScript 是否夠快?)
// Convert x to a signed 32-bit integerfunctionToInt32(x){returnx|0;}
ToInt32() 移除小數部分並套用模數 232:
> ToInt32(1.001) 1 > ToInt32(1.999) 1 > ToInt32(1) 1 > ToInt32(-1) -1 > ToInt32(Math.pow(2, 32)+1) 1 > ToInt32(Math.pow(2, 32)-1) -1
位元移位運算子
對按位元或運算有效的技巧也適用於位元移位運算子:若位移位元數為零,則位元移位運算的結果為第一個運算元,強制轉換為 32 位元整數。以下是透過位元移位運算子實作 ECMAScript 規格運算的範例:
// Convert x to a signed 32-bit integerfunctionToInt32(x){returnx<<0;}// Convert x to a signed 32-bit integerfunctionToInt32(x){returnx>>0;}// Convert x to an unsigned 32-bit integerfunctionToUint32(x){returnx>>>0;}
以下是 ToUint32() 的動作:
> ToUint32(-1) 4294967295 > ToUint32(Math.pow(2, 32)-1) 4294967295 > ToUint32(Math.pow(2, 32)) 0
我是否應該使用按位元運算子強制轉換為整數?
您必須自行決定是否值得為了略微提升效率而讓程式碼更難理解。另外,請注意按位元運算子會將自己的人為限制在 32 位元,這通常既不必要也不實用。使用其中一個 Math 函式,可能搭配 Math.abs(),會更能說明自身且可能是更好的選擇。
透過 parseInt() 取得整數
parseInt() 函式:
parseInt(str,radix?)
將字串 str(非字串會強制轉換)剖析為整數。此函式會略過開頭的空白字元,並考量找到的連續合法數字。
基底
基底的範圍為 2 ≤ radix ≤ 36。它會決定要剖析的數字的基底。若基底大於 10,除了 0–9 之外,字母也會用作數字(不區分大小寫)。
若 radix 遺失,則假設為 10,除非 str 以「0x」或「0X」開頭,這種情況下 radix 會設為 16(十六進位)
> parseInt('0xA')
10若 radix 已為 16,則十六進位字首為選用
> parseInt('0xA', 16)
10
> parseInt('A', 16)
10到目前為止,我已根據 ECMAScript 規格說明 parseInt() 的行為。此外,有些引擎會在 str 以零開頭時將基底設為 8
> parseInt('010')
8
> parseInt('0109') // ignores digits ≥ 8
8因此,最好總是明確陳述基底,並始終使用兩個引數呼叫 parseInt()。
以下是一些範例
> parseInt('')
NaN
> parseInt('zz', 36)
1295
> parseInt(' 81', 10)
81
> parseInt('12**', 10)
12
> parseInt('12.34', 10)
12
> parseInt(12.34, 10)
12不要使用 parseInt() 將數字轉換為整數。最後一個範例讓我們希望我們可以使用 parseInt() 將數字轉換為整數。唉,以下是一個轉換不正確的範例:
> parseInt(1000000000000000000000.5, 10) 1
說明
引數會先轉換為字串
> String(1000000000000000000000.5) '1e+21'
parseInt 認為「e」不是整數數字,因此在 1 之後停止剖析。以下為另一個範例
> parseInt(0.0000008, 10) 8 > String(0.0000008) '8e-7'
摘要
parseInt() 不應使用於將數字轉換為整數:強制轉換為字串是一個不必要的迂迴,而且即使如此,結果也不總是正確。
parseInt() 確實可用於剖析字串,但您必須知道它會在第一個非法數字處停止。透過 Number() 剖析字串(請參閱 函數 Number)較不寬容,但可能會產生非整數。
算術運算子
下列運算子可供 數字 使用:
-
number1 + number2 數字加法,除非其中一個運算元是字串。然後兩個運算元都會轉換為字串並串接(請參閱 加號運算子 (+))
> 3.1 + 4.3 7.4 > 4 + ' messages' '4 messages'
-
number1 - number2 - 減法。
-
number1 * number2 - 乘法。
-
number1 / number2 - 除法。
-
number1 % number2 餘數
> 9 % 7 2 > -9 % 7 -2
警告
此運算不是模數。它會傳回一個符號與第一個運算元相同的數字(稍後會提供更多詳細資料)。
-
-number - 對其運算元取負。
-
+number - 讓其運算元保持原樣;非數字會轉換為數字。
-
++variable、--variable > var x = 3; > ++x 4 > x 4
-
variable++、variable-- 遞增(或遞減)變數的值 1 並傳回它
> var x = 3; > x++ 3 > x 4
助記符:遞增 (++) 和遞減 (--) 運算子
運算元的順序可以幫助您記住它是在遞增(或遞減)之前或之後傳回。如果運算元在遞增運算子之前,它會在遞增之前傳回。如果運算元在運算子之後,它會在遞增之後傳回。(遞減運算子運作方式類似。)
位元運算子
JavaScript 有好幾個位元運算子,這些運算子可處理 32 位元整數。換句話說,這些運算子會將其運算元轉換為 32 位元整數,並產生一個 32 位元整數的結果。這些運算子的使用案例包括處理二進制通訊協定、特殊演算法等。
背景知識
本節說明幾個概念,有助於您了解位元運算子。
二進制補數
計算二進制補數 (或反碼) 的兩個常見方法如下
- 一補數
您可以透過反轉數字
x的 32 個位元來計算其一補數~x。讓我們透過四位數來說明一補數。1100的一補數為0011。將數字加到其一補數會產生一個位元皆為 1 的數字1 + ~1 = 0001 + 1110 = 1111
- 二補數
數字
x的二補數-x是其一補數加一。將數字加到其二補數會產生0(忽略最高位元以外的溢位)。以下是一個使用四位數的範例1 + -1 = 0001 + 1111 = 0000
有符號 32 位元整數
32 位元整數沒有明確的符號,但您仍可編碼負數。例如,−1 可編碼為 1 的二補數:將 1 加到結果會產生 0 (在 32 位元內)。正負數字之間的界線是流動的;4294967295 (232−1) 和 −1 在這裡是同一個整數。但當您將此類整數從 JavaScript 數字轉換為 JavaScript 數字,或從 JavaScript 數字轉換為此類整數時,您必須決定符號,因為 JavaScript 數字有明確的符號,而不是隱含的符號。因此,有符號 32 位元整數 分成兩組:
- 最高位元為 0:數字為零或正數。
- 最高位元為 1:數字為負數。
最高位元通常稱為符號位元。因此,4294967295 解釋為有符號 32 位元整數時,會在轉換為 JavaScript 數字時變成 −1
> ToInt32(4294967295) -1
ToInt32() 在 透過位元運算子處理 32 位元整數 中說明。
注意
只有無符號右位移運算子 (>>>) 可用於無符號 32 位元整數;所有其他位元運算子都可用於有符號 32 位元整數。
輸入和輸出二進制數字
在以下範例中,我們透過下列兩個運算處理二進制數字:
parseInt(str, 2)(請參閱 透過 parseInt() 處理整數)會以二進位記號 (base 2) 來剖析字串str。例如:> parseInt('110', 2) 6num.toString(2)(請參閱 Number.prototype.toString(radix?))會將數字num轉換成二進位記號的字串。例如:> 6..toString(2) '110'
按位元非運算子
~number 會計算 number 的 ones’ complement:
> (~parseInt('11111111111111111111111111111111', 2)).toString(2)
'0'二進位按位元運算子
JavaScript 有三個二進位按位元運算子
number1 & number2(按位元 And):> (parseInt('11001010', 2) & parseInt('1111', 2)).toString(2) '1010'number1 | number2(按位元 Or):> (parseInt('11001010', 2) | parseInt('1111', 2)).toString(2) '11001111'number1 ^ number2(按位元 Xor;eXcLusive Or)> (parseInt('11001010', 2) ^ parseInt('1111', 2)).toString(2) '11000101'
有兩種方式可以直觀地瞭解二進位按位元運算子
- 每一個位元一個布林運算
在下列公式中,
ni表示數字n的位元i,並將其解讀為布林值(0 為false,1 為true)。例如,20為false;21為true-
And:
resulti = number1i && number2i -
Or:
resulti = number1i || number2i Xor:
resulti = number1i ^^ number2i運算子
^^並不存在。如果存在,它會像這樣運作(如果其中一個運算元為true,則結果為true)x^^y===(x&&!y)||(!x&&y)
-
And:
-
透過
number2來變更number1的位元 -
And:只保留
number1中設定在number2的那些位元。這個運算也稱為 遮罩,其中number2為 遮罩。 -
Or:設定
number1中所有設定在number2的位元,並保持其他所有位元不變。 -
Xor:反轉
number1中所有設定在number2的位元,並保持其他所有位元不變。
-
And:只保留
按位元位移運算子
> (parseInt('1', 2) << 1).toString(2) '10'32 位元二進制數字被解釋為有號(請參閱前一節)。右移時,符號會被保留
> (parseInt('11111111111111111111111111111110', 2) >> 1).toString(2) '-1'我們已經右移了 –2。結果 –1 等於一個 32 位元整數,其位元都是 1(1 的二補數)。換句話說,一個位元的右移會將負整數和正整數都除以二。
number >>> digitCount`(無號右移)
> (parseInt('11100', 2) >>> 1).toString(2) '1110'如你所見,這個運算子從左邊移入 0。
數字建構函式的屬性
物件 Number 具有下列屬性
-
Number.MAX_VALUE 可以表示的最大正數。在內部,其小數部分的所有位元都是 1,且指數為最大值 1023。如果你嘗試透過將其乘以二來增加指數,結果將會是錯誤值
Infinity(請參閱 無限大)> Number.MAX_VALUE 1.7976931348623157e+308 > Number.MAX_VALUE * 2 Infinity
-
Number.MIN_VALUE 最小的可表示正數(大於零,一個微小的分數):
> Number.MIN_VALUE 5e-324
-
Number.NaN -
與全域
NaN相同的值。 -
Number.NEGATIVE_INFINITY > Number.NEGATIVE_INFINITY === -Infinity true
-
Number.POSITIVE_INFINITY > Number.POSITIVE_INFINITY === Infinity true
數字原型方法
所有原始數字方法 儲存在 Number.prototype 中(請參閱 原始類型從包裝類型借用其方法)。
Number.prototype.toFixed(fractionDigits?)
Number.prototype.toFixed(fractionDigits?) 傳回 數字的無指數表示,四捨五入到 fractionDigits 位數。如果省略參數,則使用值 0:
> 0.0000003.toFixed(10) '0.0000003000' > 0.0000003.toString() '3e-7'
如果數字大於或等於 1021,則此方法與 toString() 的運作方式相同。您會取得以指數表示法表示的數字
> 1234567890123456789012..toFixed() '1.2345678901234568e+21' > 1234567890123456789012..toString() '1.2345678901234568e+21'
Number.prototype.toPrecision(precision?)
Number.prototype.toPrecision(precision?) 在使用類似於 toString() 的轉換演算法之前,將尾數修剪到 precision 位數。如果未指定精度,則直接使用 toString():
> 1234..toPrecision(3) '1.23e+3' > 1234..toPrecision(4) '1234' > 1234..toPrecision(5) '1234.0' > 1.234.toPrecision(3) '1.23'
您需要使用指數表示法,才能以三位數的精度顯示 1234。
Number.prototype.toString(radix?)
對於 Number.prototype.toString(radix?),參數 radix 指出要顯示數字的系統基數。 最常見的基數為 10(十進制)、2(二進制)和 16(十六進制):
> 15..toString(2) '1111' > 65535..toString(16) 'ffff'
基數必須至少為 2,最多為 36。 任何大於 10 的基數都會導致使用字母作為數字,這說明了最大值 36,因為拉丁字母有 26 個字元:
> 1234567890..toString(36) 'kf12oi'
全域函式 parseInt (請參閱 透過 parseInt() 取得整數) 讓 您可以將此類表示法轉換回數字:
> parseInt('kf12oi', 36)
1234567890十進位指數表示法
對於基數 10,toString() 在兩種情況下使用指數表示法(小數點前只有一個數字)。首先,如果數字小數點前的數字超過 21 個
> 1234567890123456789012 1.2345678901234568e+21 > 123456789012345678901 123456789012345680000
其次,如果數字以 0. 開頭,後面接著超過五個零和一個非零數字
> 0.0000003 3e-7 > 0.000003 0.000003
在所有其他情況下,都會使用固定表示法。
Number.prototype.toExponential(fractionDigits?)
Number.prototype.toExponential(fractionDigits?) 強制數字以指數表示法表示。 fractionDigits 是介於 0 到 20 之間的數字,用來決定小數點後應顯示幾個數字。如果省略,則會包含唯一指定數字所需的有效數字。
在此範例中,我們在 toString() 也會使用指數表示法時強制使用更高的精確度。結果會混合,因為我們達到了將二進位數字轉換為十進位表示法時可達到的精確度限制
> 1234567890123456789012..toString() '1.2345678901234568e+21' > 1234567890123456789012..toExponential(20) '1.23456789012345677414e+21'
在此範例中,數字的數值大小不足以讓 toString() 顯示指數。不過,toExponential() 會顯示指數
> 1234..toString() '1234' > 1234..toExponential(5) '1.23400e+3' > 1234..toExponential() '1.234e+3'
在此範例中,當分數不夠小時,我們會得到指數表示法
> 0.003.toString() '0.003' > 0.003.toExponential(4) '3.0000e-3' > 0.003.toExponential() '3e-3'
數字函式
下列函式會對數字進行運算:
-
isFinite(number) -
檢查
number是否為實際數字(既不是Infinity也不是NaN)。有關詳細資訊,請參閱 檢查 Infinity。 -
isNaN(number) -
如果
number為NaN,則傳回true。有關詳細資訊,請參閱 陷阱:檢查值是否為 NaN。 -
parseFloat(str) -
將
str轉換為浮點數。有關詳細資訊,請參閱 parseFloat()。 -
parseInt(str, radix?) -
將
str解析為 基底為radix(2–36)的整數。有關詳細資訊,請參閱 Integers via parseInt()。
本章的來源
撰寫本章時,我參考了下列來源