19 Unicode – 簡要介紹(進階)
- 19.1 碼點與碼元
- 19.1.1 碼點
- 19.1.2 編碼 Unicode 碼點:UTF-32、UTF-16、UTF-8
- 19.2 網頁開發中使用的編碼:UTF-16 和 UTF-8
- 19.2.1 原始碼內部:UTF-16
- 19.2.2 字串:UTF-16
- 19.2.3 檔案中的原始碼:UTF-8
- 19.3 字元叢集 – 真正的字元
- 19.3.1 字元叢集與字形
Unicode 是用來表示和管理世界上大多數書寫系統中文字的標準。幾乎所有處理文字的現代軟體都支援 Unicode。此標準由 Unicode 聯盟維護。每年都會發布新版本的標準(包含新的表情符號等)。Unicode 1.0.0 版於 1991 年 10 月發布。
19.1 碼點與碼元
了解 Unicode 的兩個概念至關重要
- 碼點是表示 Unicode 文字原子部分的數字。它們大多數代表可見符號,但它們也可以有其他含義,例如指定符號的某個面向(字母的重音、表情符號的膚色等)。
- 碼元是編碼碼點的數字,用於儲存或傳輸 Unicode 文字。一個或多個碼元編碼一個碼點。每個碼元的大小相同,這取決於所使用的編碼格式。最受歡迎的格式 UTF-8 具有 8 位元碼元。
19.1.1 碼點
Unicode 的第一個版本有 16 位元碼點。從那時起,字元的數量大幅增加,碼點的大小已擴充到 21 位元。這 21 位元分為 17 個區,每個區有 16 位元
- 區 0:基本多文種平面 (BMP),0x0000–0xFFFF
- 包含幾乎所有現代語言(拉丁字元、亞洲字元等)和許多符號的字元。
- 區 1:補充多文種平面 (SMP),0x10000–0x1FFFF
- 支援歷史書寫系統(例如埃及象形文字和楔形文字)和額外的現代書寫系統。
- 支援表情符號和許多其他符號。
- 區 2:補充表意文字平面 (SIP),0x20000–0x2FFFF
- 包含額外的 CJK(中、日、韓)表意文字。
- 區 3–13:未分配
- 平面 14:補充特殊用途平面 (SSP),0xE0000–0xEFFFF
- 包含非圖形字元,例如標籤字元和字形變異選擇器。
- 平面 15–16:補充私人使用區 (S PUA A/B),0x0F0000–0x10FFFF
- 可供 ISO 和 Unicode 聯盟以外的各方指派字元。未標準化。
平面 1-16 稱為補充平面或星體平面。
讓我們檢查幾個字元的碼點
> 'A'.codePointAt(0).toString(16)
'41'
> 'ü'.codePointAt(0).toString(16)
'fc'
> 'π'.codePointAt(0).toString(16)
'3c0'
> '🙂'.codePointAt(0).toString(16)
'1f642'碼點的十六進制數字告訴我們,前三個字元位於平面 0(在 16 位元內),而表情符號位於平面 1。
19.1.2 編碼 Unicode 碼點:UTF-32、UTF-16、UTF-8
編碼碼點的主要方式有三個Unicode 轉換格式 (UTF):UTF-32、UTF-16、UTF-8。每個格式末尾的數字表示其碼單元的位元大小。
19.1.2.1 UTF-32(Unicode 轉換格式 32)
UTF-32 使用 32 位元儲存碼單元,每個碼點一個碼單元。此格式是唯一具有固定長度編碼的格式;所有其他格式都使用不同數量的碼單元來編碼單一碼點。
19.1.2.2 UTF-16(Unicode 轉換格式 16)
UTF-16 使用 16 位元碼單元。它編碼碼點如下
BMP(Unicode 的前 16 位元)儲存在單一碼單元中。
星體平面:BMP 包含 0x10_000 個碼點。由於 Unicode 總共有 0x110_000 個碼點,我們仍需要編碼剩下的 0x100_000 個碼點(20 位元)。BMP 有兩個未指派碼點的範圍,可提供必要的儲存空間
- 最高位元 10 位元(前導替代字元):0xD800-0xDBFF
- 最低位元 10 位元(後續替代字元):0xDC00-0xDFFF
換句話說,最後面的兩個十六進制數字貢獻了 8 位元。但我們只能在 BMP 以以下 2 位元組對之一開頭時使用這 8 位元
- D8、D9、DA、DB
- DC、DD、DE、DF
每個替代字元,我們有 4 對可供選擇,這就是剩餘 2 位元來自何處。
因此,每個 UTF-16 碼單元永遠都是前導替代字元、後續替代字元,或編碼 BMP 碼點。
以下是兩個 UTF-16 編碼碼點的範例
- 碼點 0x03C0 (π) 在 BMP 中,因此可以用單一 UTF-16 碼單元表示:0x03C0。
- 碼點 0x1F642 (
🙂) 在星體平面中,並用兩個碼單元表示:0xD83D 和 0xDE42。
19.1.2.3 UTF-8(Unicode 轉換格式 8)
UTF-8 具有 8 位元組代碼單位。它使用 1-4 個代碼單位來編碼一個代碼點
| 代碼點 | 代碼單位 |
|---|---|
| 0000–007F | 0bbbbbbb(7 位元組) |
| 0080–07FF | 110bbbbb, 10bbbbbb(5+6 位元組) |
| 0800–FFFF | 1110bbbb, 10bbbbbb, 10bbbbbb(4+6+6 位元組) |
| 10000–1FFFFF | 11110bbb, 10bbbbbb, 10bbbbbb, 10bbbbbb(3+6+6+6 位元組) |
註解
- 每個代碼單位的位元前綴告訴我們
- 它是否是一系列代碼單位的開頭?如果是,將會有多少個代碼單位跟隨?
- 它是否是一系列代碼單位的第二個或後面的?
- 0000–007F 範圍內的字元對應與 ASCII 相同,這導致與舊軟體具有一定程度的向後相容性。
三個範例
| 字元 | 代碼點 | 代碼單位 |
|---|---|---|
| A | 0x0041 | 01000001 |
| π | 0x03C0 | 11001111, 10000000 |
🙂 |
0x1F642 | 11110000, 10011111, 10011001, 10000010 |
19.2 網頁開發中使用的編碼:UTF-16 和 UTF-8
網頁開發中使用的 Unicode 編碼格式為:UTF-16 和 UTF-8。
19.2.1 原始碼內部:UTF-16
ECMAScript 規範在內部將原始碼表示為 UTF-16。
19.2.2 字串:UTF-16
JavaScript 字串中的字元基於 UTF-16 代碼單位
> const smiley = '🙂';
> smiley.length
2
> smiley === '\uD83D\uDE42' // code units
true有關 Unicode 和字串的更多資訊,請參閱 §20.7「文字的原子:代碼點、JavaScript 字元、字形群集」。
19.2.3 檔案中的原始碼:UTF-8
現今 HTML 和 JavaScript 幾乎總是編碼為 UTF-8。
例如,這是 HTML 檔案通常現在開始的方式
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
···對於在網頁瀏覽器中載入的 HTML 模組,標準編碼也是 UTF-8。
19.3 字形群集 - 真實的字元
一旦我們考慮到世界上的各種寫作系統,字元的概念就會變得非常複雜。這就是為什麼有幾個不同的 Unicode 術語,它們在某種程度上都表示「字元」:代碼點、字形群集、字形等。
在 Unicode 中,代碼點是文字的原子部分。
然而,字形群集最接近於顯示在螢幕或紙張上的符號。它被定義為「文字的水平可分段單位」。因此,官方 Unicode 文件也稱它為使用者感知的字元。需要一個或多個代碼點來編碼一個字形群集。
例如,天城文中的 kshi 由 4 個碼點編碼。我們使用 Array.from() 將字串分割成包含碼點的陣列(有關詳細資訊,請參閱 §20.7.1「處理碼點」)

旗幟表情符號也是字形群集,由兩個碼點組成,例如日本的國旗
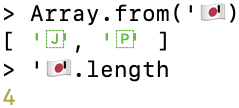
19.3.1 字形群集與字形
符號是抽象概念,也是書面語言的一部分
- 它在電腦記憶體中以 字形群集 呈現,也就是一連串一個或多個數字(碼點)。
- 它透過 字形 在螢幕上繪製。字形是一種影像,通常儲存在字型中。一個符號可能使用多個字形來繪製,例如符號「é」可以透過結合字形「e」和字形「´」來繪製。
概念與其呈現方式之間的區別很微妙,在討論 Unicode 時可能會模糊不清。
![]() 有關字形群集的更多資訊
有關字形群集的更多資訊
有關更多資訊,請參閱 Manish Goregaokar 的 “Let’s Stop Ascribing Meaning to Code Points”。
![]() 測驗
測驗
請參閱 測驗應用程式。